Lecture 5 - Applications of Deep Learning#
Deep learning has revolutionized multitude of tasks, transforming industries through its unparalleled ability to process and understand complex data. From computer vision tasks such as image and video analysis to natural language processing (NLP), time series analysis, and recommendation systems, deep learning models have redefined what is possible in AI-driven applications. By leveraging deep neural networks with multiple layers of abstraction, these systems can autonomously learn patterns and features from vast datasets, enabling unprecedented levels of accuracy and efficiency in tasks that traditionally required human intervention. This transformative technology has not only optimized processes in fields like healthcare, finance, and retail but has also paved the way for new innovations in personalized services, predictive analytics, and interactive user experiences. As a result, deep learning stands at the forefront of AI advancements, continually expanding its reach and capabilities across diverse domains, driven by its capacity to handle and interpret a wide array of data types with remarkable precision.
Group Activity#
Instruction: Look for an advanced deep learning architecture or framework (e.g., LSTM, Transformers, Autoencoders, GANs, etc.) and study how it is implemented and applied in real-world problems. Your group will prepare a presentation explaining the chosen architecture/framework and a mini case study highlighting its application in a specific field. Follow the LNCS format for the mini case study.
Deliverables:#
A group presentation on the selected advanced deep learning architecture/framework and how it works.
A mini case study report (LNCS format) about the application of the chosen deep learning approach in a particular domain.
Case Study Content Outline:#
Introduction (Contextual background and introduction of the field.)
Application of the Chosen DL Architecture (How is the architecture/framework applied in the selected field?)
Impact and Benefits (What advancements, improvements, or disruptions did this DL approach bring?)
Conclusion
Deep Learning in Computer Vision#
Deep learning has become a powerful technique for advancing computer vision capabilities. Deep learning algorithms, particularly convolutional neural networks (CNNs), excel at extracting relevant features from visual data and building complex predictive models (Geniusee, 2022).
Deep learning is used extensively in various computer vision tasks. For object detection, deep learning models like YOLO and Faster R-CNN can simultaneously locate and classify multiple objects in an image (TechTarget, 2023). Semantic segmentation models based on fully convolutional networks (FCNs) and U-Nets can precisely delineate the boundaries of objects, enabling detailed scene understanding (Run.AI, 2023). Deep learning also enables effective image classification, localization, pose estimation, image style transfer, colorization, reconstruction, and synthesis (Sciencedirect, 2021).
The key advantage of deep learning for computer vision is its ability to automatically learn hierarchical visual features from large datasets, without the need for manual feature engineering (IBM, 2023). Deep neural networks can discover low-level features like edges and textures, and progressively build up to higher-level semantic concepts. This end-to-end learning approach has led to significant performance improvements across a wide range of computer vision applications.
In this section, we will introduce the Convolutional Neural Network, also known as CNN or ConvNets, as a better way for dealing with image classification, detection, segmentation, computer vision, and other tasks involving image datasets. We will also learn the image data and its composition.
Image Data#
It is first important to define the input shape of an image, which will be (input channels, image height, image width). Let’s say given an image of 14 x 14 pixels = 196 features like this. Each data point is an array of numbers describing how dark each pixel is, where value range from 0 to 255. These values can be normalized ranging from 0 to 1.
import cv2
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib inline
plt.imshow(np.random.randint(0,256, (250,250, 3)))
plt.show()
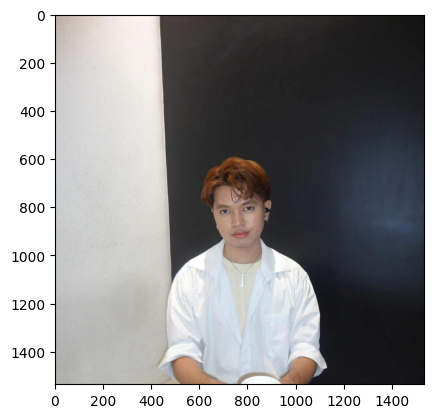
# reading an image file using matplotlib
hagrid = plt.imread('./d0277596-4b93-4d74-9afa-7ee5000e169f.jpg')
# accessing the first line from the top of the image
# this image have three channels (r, g, b)
print(hagrid[0, :, :])
print(hagrid[0, :, :].shape)
[[185 172 163]
[185 172 163]
[184 171 162]
...
[ 20 20 20]
[ 20 20 20]
[ 20 20 20]]
(1536, 3)
Images are actually just n-dimensional arrays.
There are multiple ways of displaying an image in python, one of which is by using thematplotlib.pyplot.imshow() function.
plt.imshow(hagrid)
plt.show()
# accessing the height, width and the channel component of an image
h, w, c = hagrid.shape
print(f"height: {h}, width: {w}, channel: {c}")
height: 1536, width: 1536, channel: 3
An image data consists of the width and height of an image by pixel unit, another value that can be seen is the color channel of an image.
In the context of images, a “channel” refers to a specific component of the image’s color information. Images are often composed of multiple channels, each representing different aspects of the image’s appearance or color. The most common image channel representations are:
Grayscale (1-channel)
RGB: Red-Green-Blue (3-channel)
CMYK: Cyan-Magenta-Yellow-Key (4-channel)
HSV: Hue-Saturation-Value (3-channel)
RGBA: Red-Green-Blue-Alpha (4-channel)
# reading image file using opencv
# pip install opencv-python
plt.imshow(cv2.imread("./d0277596-4b93-4d74-9afa-7ee5000e169f.jpg"));
plt.show()
NOTE:
matplotlibresulting image follows an RGB format.open-cvresulting image follows BGR format.When using
open-cv, you can use its built-incvtColor()class to convert the color of an image.
# cv2 image converted from BGR to RGB
img = cv2.imread('.\d0277596-4b93-4d74-9afa-7ee5000e169f.jpg')
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
<>:3: SyntaxWarning: invalid escape sequence '\d'
<>:3: SyntaxWarning: invalid escape sequence '\d'
C:\Users\ccdan\AppData\Local\Temp\ipykernel_8636\4294468529.py:3: SyntaxWarning: invalid escape sequence '\d'
img = cv2.imread('.\d0277596-4b93-4d74-9afa-7ee5000e169f.jpg')
plt.imshow(rgb_img)
plt.show()
QUESTION:
How many color channels does this Dolores Umbridge image have?
dolores = plt.imread('./dolores.jpg')
plt.imshow(dolores, cmap='BuPu_r')
plt.show()

print(dolores.shape)
(3456, 4608, 3)
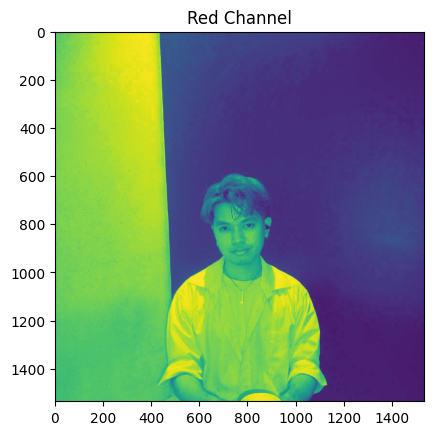
NOTE: An image that appears to be black and white or grayscale with literal hues of gray, white, and black color typically has three channels due to the way color images are represented in digital form.
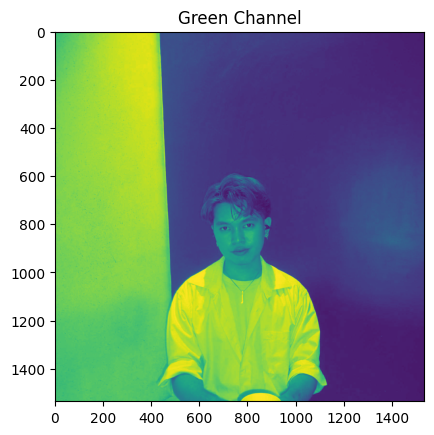
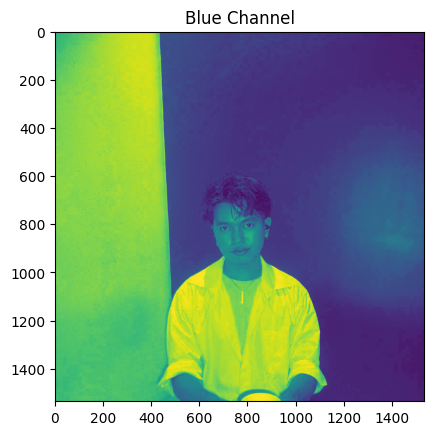
for channel, color in zip(range(3), ['Red', 'Green', 'Blue']):
plt.imshow(dolores[:, :, channel])
plt.title(f"{color} Channel")
plt.show()



Interestingly, images in literal grayscale have the same values for all its channel.
for channel, color in zip(range(3), ['Red', 'Green', 'Blue']):
plt.imshow(hagrid[:, :, channel])
plt.title(f"{color} Channel")
plt.show()
Reshaping image data is just like reshaping an array or a matrix.
Resize can increase or decrease the size of the image. For example, you can resize image from 100x100 to 20x20. Reshape changes the shape of the image without changing the total size. For example, you can reshape image from 100x100 to 10x1000 or to 1x100x100.
Answered by Andrey Lukyanenko (Stack Overflow)
# stretchy Hagrid!
plt.imshow(cv2.resize(hagrid, (200, 200)))
plt.show()
REMEMBER: When you resize an image, the visible features can be stretched or distorted, and it’s crucial to consider the implications of this operation.
Imagine you’re teaching a magical creature recognition spell to your model using peculiar, twisted images of Hagrid. If you only show it these odd, distorted versions of everyone’s favorite half-giant, your model might become so enchanted by these peculiarities that it’ll fumble and misfire when confronted with the true, undistorted Hagrid! Remember, in the world of AI, your model can only learn what you teach it, so make sure it’s learning from the right magical scrolls!
Convolutional Neural Network#
The CNNs emerged from the study of the brain’s visual cortex, and have been used in image recognition since 1980s. CNNs are also successful in implementing voice recognition and natural language processing. However, we will focus on visual applications for now.
Why CNN?#
Image data are well-suited for training with Convolutional Neural Networks (CNNs) because images can be represented as matrix-like data, allowing CNNs to effectively capture spatial patterns and hierarchical features within the data.
1. Convolution Layer#
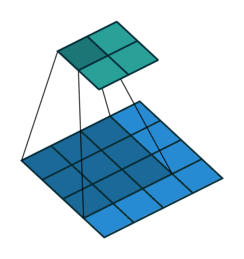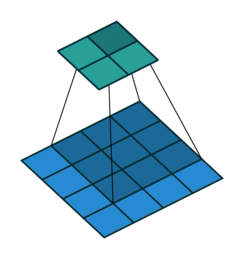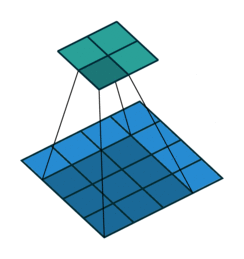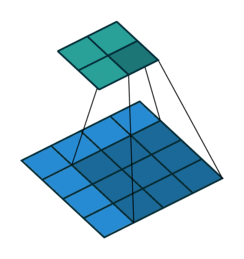
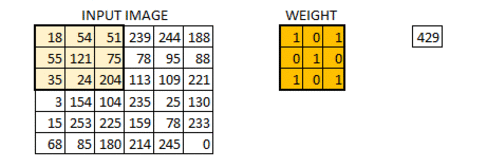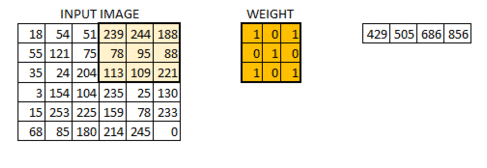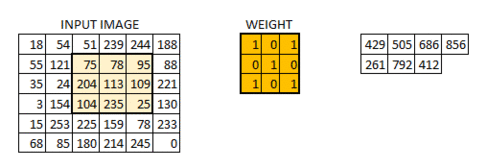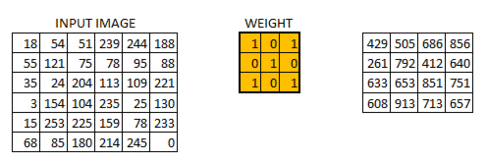
The most important building block of a CNN is the convolutional layer. It is a mathematical operation that slides one function over another and measures the integral of their pointwise multiplication. Convolutional network works on the central concept of a convolution operation like this:
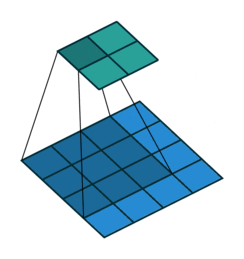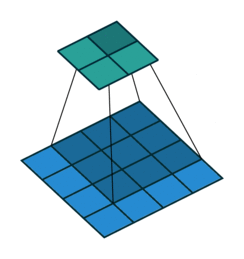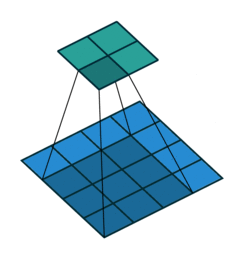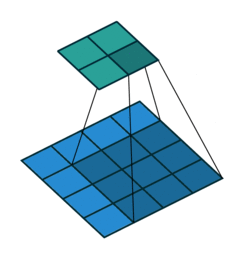
Mathematically, it looks like this:
Let’s say we have a 5 x 5 input image \(I\) of channel 0 of batch 0. Hence, its shape is (0, 0, 5, 5):
Each of this pixel may represent the brightness ranging from 0 to 255. Or if normalized, shall be 0 to 1.
If we define a 3 x 3 patch which we commonly called weights (W) or in computer vision, we called filters/kernels like this (we shall called filters in this lecture note for simplicity):
Let’s say we are scanning the middle of the image, then the output feature would be (we’ll denote this as \(o_{33}\)):
This will result in one output feature called feature map. Of course, we may add bias to it and then will be fed through an activation function.
Actual feature maps look like this. Each feature map is a output of a single training example and convolve each kernel over the sample. In simple words, if we have \(k\) filters, then we have \(k\) feature maps. They represent the activation part corresponding to the kernels.

In using PyTorch, we primarily use the script:
torch.nn.Conv2d(input_channels, output_channels, kernel_size, stride=1, padding=0)
A. Filters#
1. How the filters look like? It turns out that each filter actually detects the presence of certain visual patterns. For example, this filter below detects whether there is an edge at that location of the image. There are also other similar filters detecting corners, lines, etc. Check out https://setosa.io/ev/image-kernels/ and try changing the values.
{kind=link}
Real filters can look like this. They may look somewhat random at first glance, but we can see that clear structure being learned in most kernels. For example, filters 3 and 4 seem to be learning diagonal edges in opposite directions, and others capture round edges or enclosed spaces:

However, it is important to note that we DON’T need to decide the filters to use. We can simply feed a randomly generated filter, and it is the job of CNN to learn these filters. These learned filters will learn what features are most efficient for the classification process.
What is the shape of filters?
For each image, we can apply multiple filters, depending on how many output channels we want.
Let’s say the input channel is 3, and we want the output channel to be 64, then we apply a filter of size (3, 64, filter width, filter height).
Hence, torch.nn.Conv2d(3, 64, filter_width, filter_height).
Do not be confused with the Conv2d and PyTorch image shape.
Conv2d:torch.nn.Conv2d(input_channels, output_channels, kernel_size, stride=1, padding=0)Image shape:
(input_channels, image_height, image_width)
How do we know how many output channels to use? The answer is we don’t know… we just try and see what works. More filters allow the network to look at more patterns.
What should be the filter size? If we use a 3 x 3 filter, each pixel gets 8 neighboring information. On the other hand, if we use a big filter like 9 x 9, then we get 80 neighboring information. In research and industry, the typical filter sizes are \(3 \times 3\) or \(5 \times 5\).
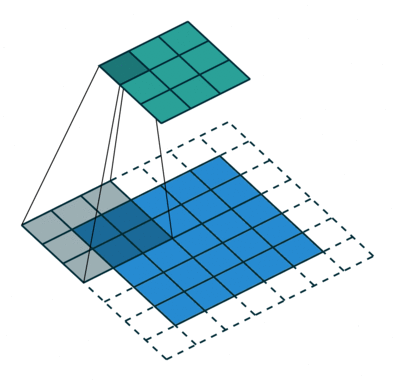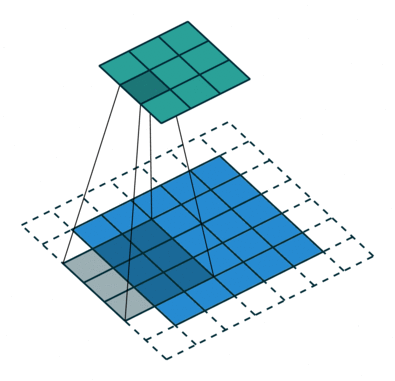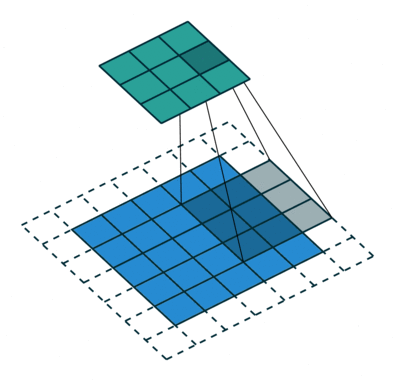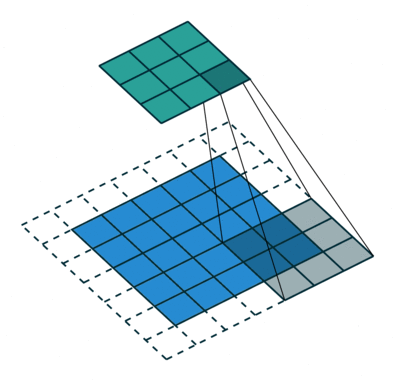
B. Padding#
2. How should we convolve the edges? Recall this image:
It has 4 x 4 pixels = 16 features. But after convolution, we only got 2 x 2 pixels = 4 features left. Is that good? There are no correct answers here but we are quite sure that we lose some information. One way to address this is padding, where we can enlarge the input image by padding the surroundings with zeros. How much? Padding until we get the original size or larger size, for example, like this:
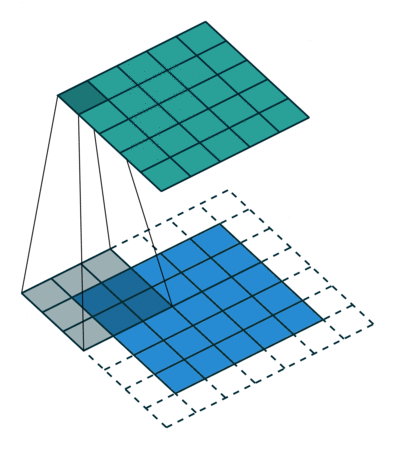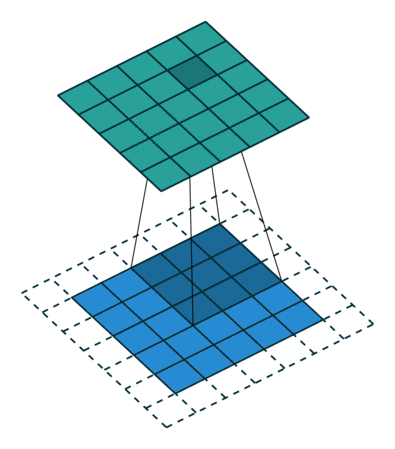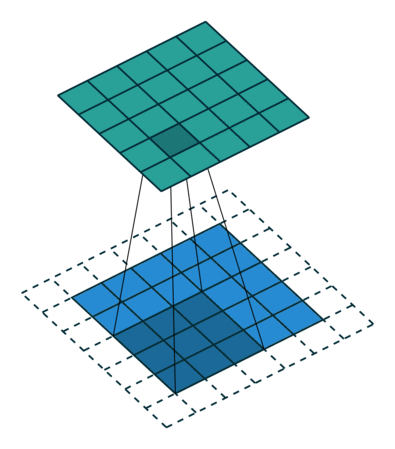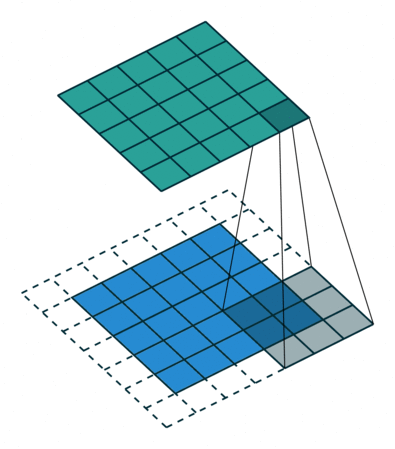
The below put even more padding which pad to make sure each single pixel is convoluted (full padding), which results in the output features being even larger:
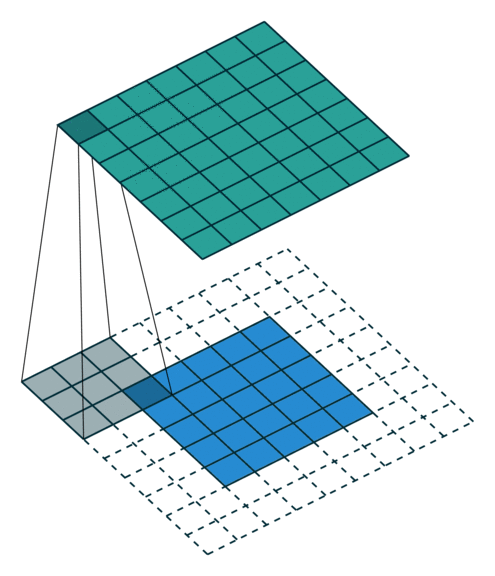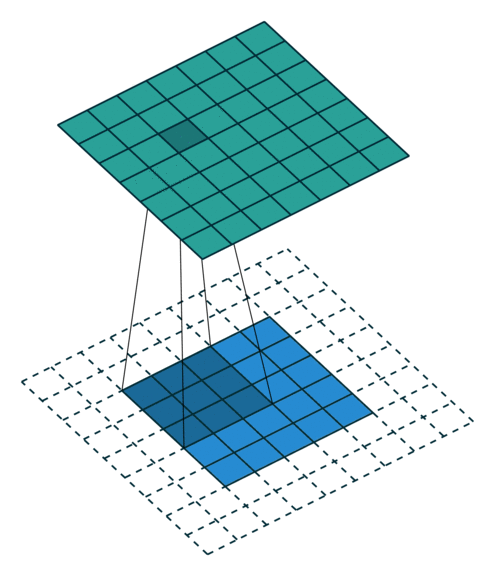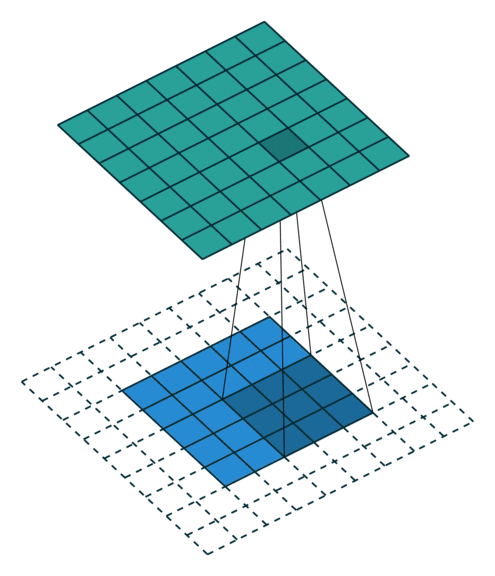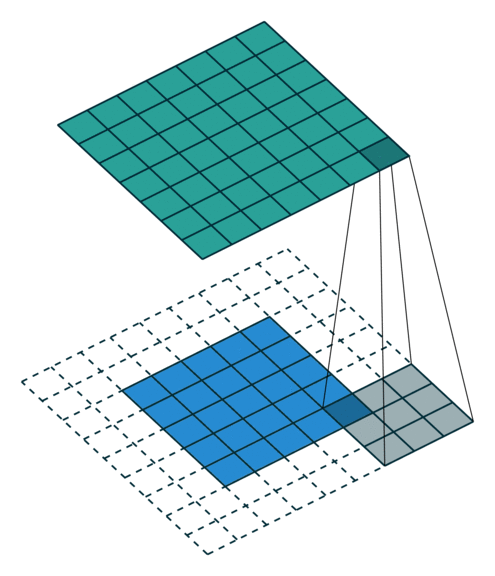
C. Strides#
3. How many steps should we take to slide our filter? Skip 2? Should we shift 1 step per convolution, or 2 steps, or how many steps. In fact, it really depends on how detailed you want it to be. But defining bigger steps reduces the feature size and thus reduces the computation time. Bigger step is like human scanning a picture more roughly but can reduce the computation time… whether to use it is something to be experimented though.
No padding with stride of 2:
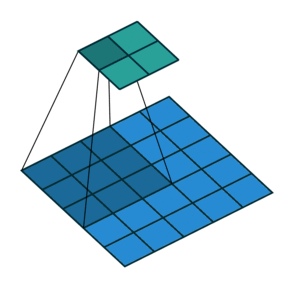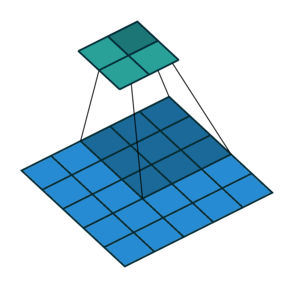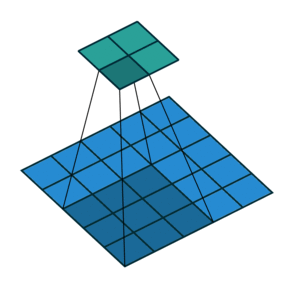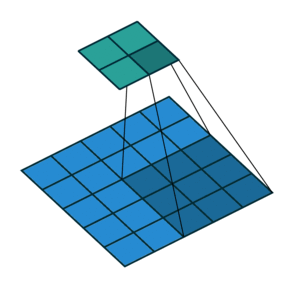
Padding with stride of 2:
Actual image convolution can look like this (with stride 1 and no padding):
The convoluted image may look like this (nothing related with the above matrix though):

The formula to be used to measure the padding value to get the spatial size of the input and output volume to be the same with stride 1 is:
where \(K\) is the filter size. This means that if our image is size \(24 \times 24\), and the filter size is \(3 \times 3\), then our \(K\) has size 3 so the padding should be \(\frac{(3-1)}{2} = 1\), then we need to add a border of one pixel valued 0 around the outside of the image, which would result in the input image of size \(26 \times 26\).
D. Shape#
4. What would be the shape of the output matrix? The output shape (denote as \(O\)) depends on the stride (denote as \(S\)), padding (denote as \(P\)), filter size (denote as \(F\)), as well as the input width and height (denote as \(I\)). \(O\) can be calculated with the formula as follows:
In this case (code below), if our \(W\) is 28, \(F\) is 5, \(P\) is 2, and \(S\) is 1 then the width/height is 28.
In conclusion,
The input will have a 4D shape of (batch size, input channels, input height, input width).
The output will have a 4D shape of (batch size, output channels, output height, output width).
The convolutional filters will have a 4D shape of (input channels, output channels, filter height, filter width).
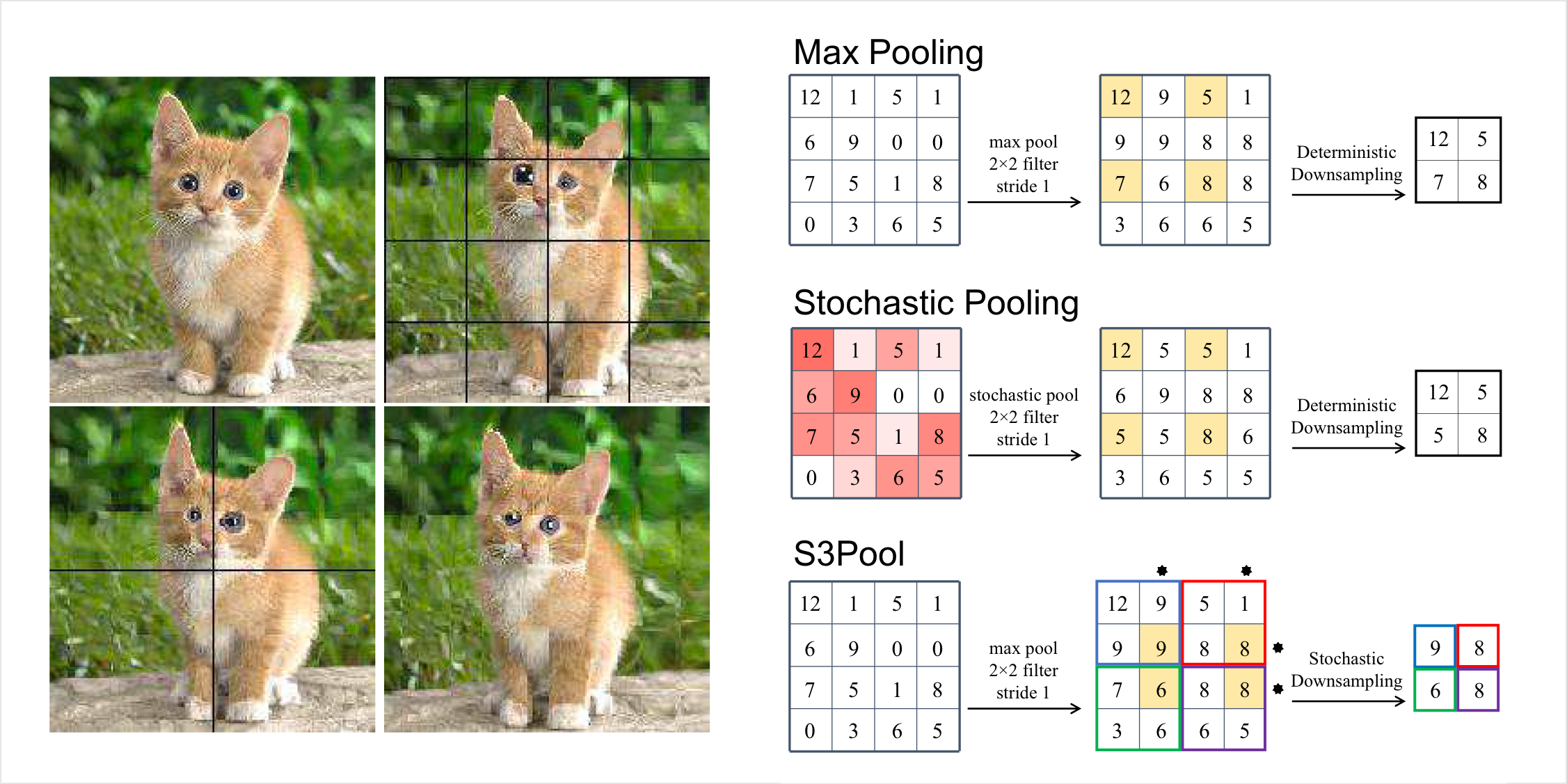
2. Max/Average Pooling Layer#
Talking about reducing computation time, a common way is to perform a pooling layer which simply downsamples the image by averaging a set of pixels, or by taking the maximum value. If we define a pooling size of 2, this involves mapping each 2 x 2 pixels to one output, like this:
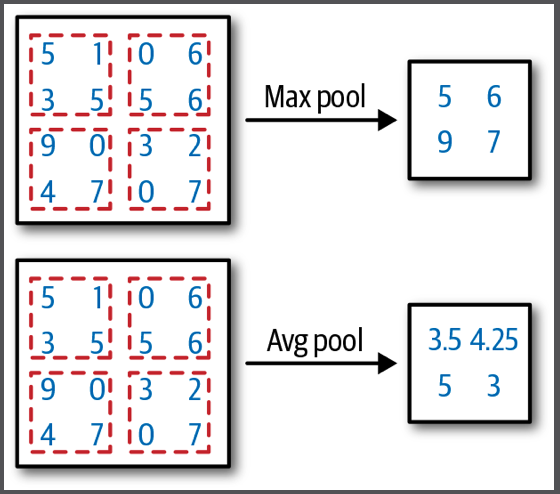
Nevertheless, pooling has a really big downside, i.e., it basically loses a lot of information. Compared to strides, strides simply scan less but maintain the same resolution, but pooling simply reduces the resolution of the images.
As Geoffrey Hinton said on Reddit AMA in 2014 - The pooling operation used in CNN is a big mistake and the fact that it works so well is a disaster. In fact, in most recent CNN architectures like ResNets, it uses pooling very minimally or not at all.
The maximum pooling layer for 2D images over an input signal can be used through this script:
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0)
3. BatchNorm Layer#
Batch norm is nothing other than normalizing samples within the batch. That is, minus the mean of features within the batch. This helps with unstable gradients in SGD. Note that the output size does not change from input size after BatchNorm.

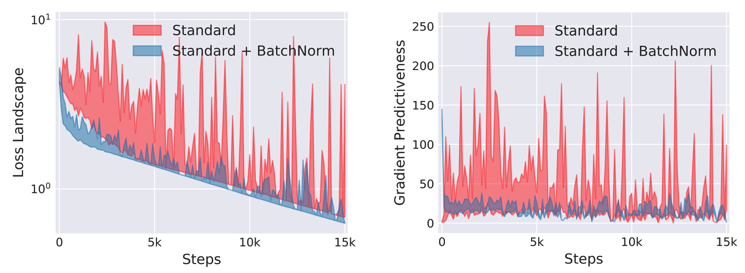
Advantages
Speeds up training
Allows sub-optimal starts
Acts as a regularizer (a little)
4. Dropout Layer#
This is a layer of arbitrarily removing some values in your data. By randomly removing data in each iteration, you make the neural network more robust against overfitting, because it needs to learn to fight with incomplete data.
For example, say we have a vector of \(x = \{1, 2, 3, 4, 5\}\). Let’s set \(p = 0.2\) which means 20% of data will be turned to 0. In training mode, \(x_{train} = \{1, 0, 3, 4, 5\}\); do not confuse why I turn off 2 and not others, I just turn 20% off randomly. In evaluation mode, we turn off dropout, but to make sure the distribution remains similar, we multiply the values by \(1 - 0.2 = 0.8\), which becomes \(x_{inference} = \{0.8, 1.6, 2.4, 3.2, 4.0\}\).